Penerapan Metode RFM untuk Customer Lifetime Value Menggunakan K-Means
- Adib Ahmad Istiqlal
- Sep 22, 2022
- 6 min read

CLV adalah nilai sekarang dari ekspektasi keuntungan atau kerugian yang akan diperoleh perusahaan selama melakukan transaksi dengan konsumen. Pendekatan ini yang dianggap paling baik, Keuntungan yang didapat oleh suatu perusahaan tidak hanya dipengaruhi oleh lama dan banyaknya konsumen, tetapi juga dari kualitas konsumen tersebut. sehingga terjadi perubahan paradigma dalam pengambilan keputusan bisnis suatu perusahaan. Namun tidak mudah untuk mengetahui bagaimana cara perusahaan menentukan CLV yang baik untuk diakuisisi, diretensi dan dikembangkan. Oleh karena itu dibutuhkan analisis, salah satu metode yang dapat digunakan adalah analisis cluster. Analisis Cluster atau Clustering merupakan salah satu metode pada analisis multivariat, yang memiliki tujuan untuk mengelompokkan objek-objek berdasarkan karakteristik yang dimilikinya.
Business Understanding
Pada pernyataan yang telah dijelaskan, sehingga masalah yang diangkat adalah
Bagaimana estimasi nilai CLV terhadap konsumen
Bagaimana melakukan segmentasi konsumen menggunakan K-Means
Bagaimana pengaruh hasil segmentasi berdasarkan negara asal konsumen
Tujuan dari masalah yang diangkat adalah
Mengestimasi nilai CLV berdasarkan recency, frequency dan monetary/revenue yang dihasilkan konsumen
Melakukan segmentasi menggunakan machine learning unsupervised.
Data Understanding
Dataset yang digunakan pada penelitian ini adalah dataset pakaian secara online yang dapat dilakukan dari website atau app. Sumber dataset ini berasal dari UCI Machine Learning Repository Adapun kolom-kolom pada dataset ini, antara lain
InvoiceNo: Nomor faktur. Nominal, nomor integral 6 digit yang ditetapkan secara unik untuk setiap transaksi. Jika kode ini dimulai dengan huruf 'c', itu menunjukkan pembatalan.
StockCode: Kode produk (barang). Nominal, bilangan integral 5 digit yang ditetapkan secara unik untuk setiap produk yang berbeda.
Desctription: Nama produk (barang). Nominal.
Quantity: Jumlah setiap produk (item) per transaksi. numerik.
Tanggal: Tanggal dan waktu Faktur. Numerik, hari dan waktu saat setiap transaksi dibuat.
Unit Price: Harga satuan. Numerik, Harga produk per unit dalam sterling.
Customer ID: Nomor pelanggan. Nominal, nomor integral 5 digit yang ditetapkan secara unik untuk setiap pelanggan.
Country: Nama negara. Nominal, nama negara tempat tinggal setiap pelanggan.
Pada kolom diatas, tediri dari 541909 baris dan 8 kolom yang terdiri dari 3 tipe data integer, 4 tipe object dan 1 tipe datetime

Info dataset

CustomerID berisi tentang ID dari Customer dan ID merupakan sebuah identitas dan tidak bisa dilakukan aritmatika pada nilainya. Sehingga lebih cocok dirubah kedalam bentuk string. Namun diperlukan pengubahan terlebih dahulu ke integer untuk menghilangkan satuan desimalnya.
df['CustomerID'] = df['CustomerID'].astype(int)
df['CustomerID'] = df['CustomerID'].astype(str)
df.info()2. Menghapus Missing Values
data = {
'Nominal' : df.isnull().sum(),
'Persen' : round(100*(df.isnull().sum())/len(df),2)
}
df_null = pd.DataFrame(data = data, index = df.columns)
df_null
Pada dataset terdapat 136534 data bersifat null dan akan dilakukan penghapus pada data yang bersifat null. Khususnya CustomerID memiliki missing-value bertotal 135 ribu lebih dan Description memiliki missing value 1454. CustomerID memiliki hampir 25% total missing value dari total jumlah data.
df = df.dropna()
df.shapeHasil penghapus data null menghasilkan sisa data 406829 bari dan 8 kolom. Selanjutnya perubahan tipe data menjadi date pada kolom InvoiceDate dengan mengambil hanya tanggal saja tanpa time.
df['InvoiceDate'] = pd.to_datetime(df['InvoiceDate']).dt.normalize()
df.head()Data Preparation
Tahapan selanjutnya dilakukan tahapan Customer Lifetime Value (CLV). CLV adalah cara untuk mengatur hubungan perusahaan dengan konsumennya melalui siklus kehidupan konsumen dan salah satu teknik yang dapat digunakan adalah Receny, Frequency dan Monetary (RFM). RFM merupakan metode analisis yang digunakan membuat segmentasi konsumen menjadi kelas-kelas tertentu dan berikut identitas satu per satu dari RFM.
1. Receny : mengindikasikan pelanggan telah membeli sesuatu baru-baru ini. Pelanggan yang membeli belum lama ini lebih cenderung bereaksi terhadap penawaran baru daripada pelanggan yang transaksi pembeliannya sudah terjadi sejak lama.
2. Frequency : memperlihatkan banyaknya pembelian yang dilakukan konsumen. Jika pelanggan melakukan pembelian lebih sering, hal itu akan menghasilkan respon lebih positif lebih tinggi daripada pelanggan yang jarang membeli sesuatu.
3. Monetary Value : omset pembelian atau nilai moneter mengacu pada semua pembelian yang dilakukan oleh pelanggan. Pelanggan yang menghabiskan lebih banyak uang untuk pembelian lebih cenderung menanggapi penawaran daripada pelanggan yang telah menghasilkan jumlah yang lebih kecil.
Penjelasan di atas dapat disimpulkan bahwasanya untuk mendapat nilai pada RFM ialah
1. Receny : Hasil terkecil hasil tanggal terakhir pada dataset - tanggal terakhir pada tiap konsumen
2. Frequency : Banyaknya teransaksi dari jumlah tanggal pembelian konsumen
3. Monetary : Total dari (Total pemesanan * Harga) dari seluruh pembelian konsumen.
Pembuatan Receny
df['last_date'] = max(df['InvoiceDate']) - df['InvoiceDate']
df_Receny = df.groupby('CustomerID')['last_date'].min()
df_Receny = df_Receny.reset_index()
df_Receny.columns = ['CustomerID', 'Receny']
#Ekstrak angkanya saja
df_Receny['Receny'] = df_Receny['Receny'].dt.days
df_Receny

Pembuatan Frequency
df_frequency = df.groupby('CustomerID')['InvoiceDate'].count()
df_frequency = df_frequency.reset_index()
df_frequency.columns = ['CustomerID', 'Frequency']
df_frequency.head()
Pembuatan Moneraty
df['Mone'] = df['UnitPrice'] * df['Quantity']
df_Moneraty = df.groupby('CustomerID')['Mone'].sum()
df_Moneraty = df_Moneraty.reset_index()
df_Moneraty.columns = ['CustomerID', 'Moneraty']
df_Moneraty.head()
Setelah Receny, Frequency, dan Moneraty selesai dilakukan. Saya akan mengambil contoh 1 CustomerID untuk menjelaskan.

Bisa dilihat jika eksplorasi lebih dalam bahwasanya
1. Receny dari ID 12346 nilai terkecil dari tanggal terakhir nya adalah 325
2. Memiliki frekuensi transaksi terakhir berjumlah 2 kali pada tanggal 18 Januari 2011
3. Dan Moneraty nya memiliki + (plus) dan - (minus) pada Mone, sehingga dijumlahkan menghasilkan Moneraty = 0.
Setelah membuat data-data RFM tersebut, maka akan dilakukan penggabungan.
df_rfm = df_Receny.merge(df_frequency, on = 'CustomerID').merge(df_Moneraty, on = 'CustomerID')
print("Struktur dari Dataset :", df_rfm.shape)
df_rfm.head()
Pada hasil di atas bahwasanya total konsumen (setelah pembersihan data) berjumlah 4372 konsumen. Selanjutnya akan dilihat persebaran data dari Receny, Frequency, dan Moneraty.
print(df_rfm.describe().T)
fig, ax = plt.subplots(1,3, figsize = (20,5))
color = ['red', 'orange', 'blue']
j = 0
for i, ax, c in zip(df_rfm.select_dtypes(include = 'number'), ax.flatten(), color):
sns.histplot(df_rfm[i], ax = ax, color = c, bins = 30)
Hasil di atas menunjukkan bahwasanya
1. Nilai Receny, Frequency, dan Moneraty berdistribusi menceng ke kanan (Right Skewed)
a. Receny: Mean = 91.6, Median = 50, dan std = 100.772
b. Frequency: Mean = 93.05, Median = 42, dan std = 232.471
c. Moneraty: Mean = 1898.5, Median = 648.075, dan std = 8219.345
2. Dapat dinyatakan bahwa akhir-akhir ini banyak customer yang melakukan transaksi. Pada Receny, banya konsumen yang belum melakukan transaksi terakhirnya. Dimulai dari > 125 hari transaksi terakhirnya
3. Transaksi baru-baru ini kebanyak konsumen melakukan 30 transaksi dengan kurang rata-rata moneraty 1898.5
Modeling
Segementasi yang dilakukan pada projek ini dengan cara meng-cluster pada ketiga kolom hasil penggabungan. Untuk itu akan dilakukan terlebih dahulu pencarian nilai k optimal menggunakan elbow dan sillhouette
Elbow
optim = []
#Elbow
for k in range(2,19):
model = KMeans(n_clusters = k)
model.fit_predict(df_rfm.select_dtypes(include = 'number'))
optim.append(model.inertia_)
plt.plot(range(2,19),optim)
Pada hasil Elbow tersebut, sulit menemukan siku (elbow) pada garisnya. Sehingga dibutuhkan Silhouette untuk melihat angka pastinya.
Silhouette
score = []
for k in range(2,19):
model = KMeans(n_clusters = k)
label = model.fit_predict(df_rfm.select_dtypes(include = 'number'))
silhouette = silhouette_score(df_rfm.select_dtypes(include = 'number'), label, metric = 'euclidean')
score.append(silhouette)
print("For n_cluster = {} , silhouette score = {}".format(k, silhouette))
plt.plot(range(2,19),score)
Nilai dari Sillhouette ada diantara -1 sampai dengan 1. Jika nilainya mendekati angka 1, maka titik data akan sangat mirip dengan titik data lainnya di cluster yang sama. Jika mendekati -1 maka titik data tersebut tidak mirip dengan titik data di klusternya.
Hasil di atas bahwasanya nilai K terbaik berada pada K = 2. Hal ini dikarenakan sifat antar data yang mirip, namun segmentasi yang dilakukan per tiap variabel R,F,M. Sehingga, projek ini akan menggunakan K = 3 dan nilai silhouette menunjukkan K = 3 masih lebih > 0.95 dan artinya masih mendekati satu.
model = KMeans(n_clusters = 3)Receny Level
df_Receny_Pred = df_Receny.copy()
df_Receny_Pred['Cluster'] = model.fit_predict(df_Receny_Pred.select_dtypes(include = 'number'))
df_Receny_Pred_Group = df_Receny_Pred.groupby('Cluster')['Receny'].mean()
df_Receny_Pred_Group = df_Receny_Pred_Group.reset_index()
df_Receny_Pred_Group.columns = ['Cluster', 'Means']
df_Receny_Pred_Group
Frequency Level
df_Frequency_Pred = df_frequency.copy()
df_Frequency_Pred['Cluster'] = model.fit_predict(df_Frequency_Pred.select_dtypes(include = 'number'))
df_Frequency_Pred_Group = df_Frequency_Pred.groupby('Cluster')['Frequency'].mean()
df_Frequency_Pred_Group = df_Frequency_Pred_Group.reset_index()
df_Frequency_Pred_Group.columns = ['Cluster', 'Means']
df_Frequency_Pred_GroupMoneraty Level
df_Moneraty_Pred = df_Moneraty.copy()
df_Moneraty_Pred['Cluster'] = model.fit_predict(df_Moneraty_Pred.select_dtypes(include = 'number'))
df_Moneraty_Pred_Group = df_Moneraty_Pred.groupby('Cluster')['Moneraty'].mean()
df_Moneraty_Pred_Group = df_Moneraty_Pred_Group.reset_index()
df_Moneraty_Pred_Group.columns = ['Cluster', 'Means']
df_Moneraty_Pred_GroupPenggabungan RFM Level
df_RFM_level = df_Receny_Pred_Group.merge(df_Frequency_Pred_Group, on = 'Cluster').merge(df_Moneraty_Pred_Group, on = 'Cluster')
df_RFM_level.columns = ['Cluster','Mean_Receny', 'Mean_Freq', 'Mean_Moneraty']
df_RFM_level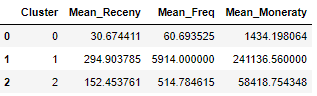
Setelah penentuan cluster dan mendapatkan nilai Mean untuk tiap-tiap Cluster, maka diperlukan pemberian level dengan syarat.
1. Receny:
a. Receny <= 30.674411 --> Cluster 1 (Level 2)
b. Receny > 30.674411 AND Receny <= 152.453761 --> Cluster 2 (Level 1)
c. Receny > 152.453761 --> Cluster 0 (Level 0)
<br>
2. Frequency:
a. Frequency <= 60.693525 --> Cluster 0 (Level 0)
b. Frequency > 60.693525 AND Frequency <= 514.784615 --> Cluster 2 (Level 1)
c. Frequency > 152.453761 --> Cluster 1 (Level 2)
<br>
3. Moneraty:
a. Frequency <= 1434.198064 --> Cluster 0 (Level 0)
b. Frequency > 1434.198064 AND Frequency <= 58418.754348 --> Cluster 2 (Level 1)
c. Frequency > 58418.754348 --> Cluster 1 (Level 2)
<br>
Dimana ketentuan level adalah
1. Level 2 --> High
2. Level 1 --> Medium
3. Level 0 --> Low
Sehingga total dari RFM Segmentasi nya terdiri dari 0 hingga 6 yang didapatkan dari
RFM Segmentasi = Receny Level + Frequency Level + Moneraty Level |
dimana 0 hingga 6 memiliki arti
1. 0 --> Tidak Loyalti
2. 1 dan 2 --> Loyalti Rendah
3. 3 dan 4 --> Loyalti Sedang
4. 5 dan 6 --> Loyalti Tinggi
RFM Segmentasi
df_RFM_Segmen = df_receny_level.merge(df_Frequency_level, on = 'CustomerID').merge(df_Moneraty_level, on = 'CustomerID')
df_RFM_Segmen = df_RFM_Segmen[['CustomerID','Receny_Level', 'Frequency_Level', 'Moneraty_Level']]
df_RFM_Segmen['RFM_Level'] = df_RFM_Segmen['Receny_Level'] + df_RFM_Segmen['Frequency_Level'] + df_RFM_Segmen['Moneraty_Level']
df_RFM_Segmen
Setelah membuat data frame untuk RFM Segmentasi, akan dihitung frekuensi per kategori

Pada plot di atas dapat disimpulkan bahwasanya
1. Jumlah konsumen tersebar pada golongan Tidak Loyalti dan Loyalti Rendah
2. Kategori Layolti Sedang memiliki proporsi yang hampir sama
3. Pada kategori Loyalti Tinggi memiliki proporsi kurang dari 100. Dimana total kategori 6 hanya berjumlah 7 konsumen
4. Sehingga konsumen yang dimiliki perusahaan saat ini kebanyakan tidak terlalu royal pada produk yang dihasilkan perusahaan
Analisis Berdasarkan Negara Asal Konsumen

Hasil visualisasi di atas menunjukkan bahwasanya UK merupakan jumah konsumen tertinggi pada perusahaan. Mari kita eksplor lebih dalam kategori apa saja yang ada di dalamnya
plt.figure(figsize = (25, 10))
df_RFM_uk = df_RFM_country[df_RFM_country['Country'] == 'United Kingdom']
sns.countplot(df_RFM_uk['RFM_Level'])
plt.xlabel('Kategori', fontsize = 20, labelpad = 15)
plt.ylabel('Proporsi', fontsize = 20, labelpad = 15)
plt.xticks(fontsize = 25)
plt.yticks(fontsize = 25)
plt.show()
Hasil visualisasi dapat disimpulkan bahwasanya
1. United Kingdom lebih banyak menyumbang konsumen yang hampir menyentuh 90% dari total konsumen yang dimiliki perusahaan
2. Dimana dari jumlah 7 konsumen pada kategori 6, UK menyumbang 3 konsumen pada kategori tersebut. Sisanya berada pada negara Australia, Belanda, dan EIRE
3. Sehingga dapat disimpulkan, bahwasanya peluang tertinggi untuk meningkatkan transaksi konsumen terhadap perusahaan berada pada negara UK. Namun untuk negara lain dapat dilakukan analisis marketing yang lebih dalam yang dapat dilihat salah satunya dari karakteristik tiap negara.
Codingan lengkap dan dataset, silihakan klik button dibawah ini.



Comments